INDEX
1. 시작하며
지식 그래프는 학부연구생을 시작하고 나서 처음으로 하나의 주제에 집중적으로 투자하게 된 분야이다. 지식 그래프의 완성을 목표로 하는 knowledge graph completion(이하 KGC)라는 분야이다. 본 글은 약 3개월간 KGC를 다룬 모델들과 그에 따른 추가적 생각들에 대한 정리글이다. 해당글은 tutorial 자료[1]로 공부한 바탕으로 만들어졌음을 알리고 싶다.
2. 지식 그래프
지식 그래프(이하 KG)란 무엇일까. KG는 일반 그래프에서 노드를 entity, 간선을 relation으로 구성하고 있는 hetrogeneous 그래프이다. 이 설명만으로는 이해하기 힘들기 때문에 일반 그래프와 비교하며 살펴보자.
일반 그래프 : 노드는 하나의 개체이다. 이는 사람, 사물, 개념 등 여러 가지 종류가 올 수 있다. 간선은 노드를 이어주는 역할로 노드 사이의 관계를 정의할 수 있다. 주로 간선은 방향, 무방향으로 분류된다. 간선을 통해 어떤 노드가 어떤 노드에 영향을 주고 있는지 또는 받고 있는지 나타낼 수 있고 무방향으로 연결된 두 노드 사이의 동등한 연결관계를 나타낼 수 있다.
KG : 노드는 하나의 개체이다. 하지만 KG에서는 주로 entity로 불린다. 간선이 바로 일반 그래프와의 극명한 차이점을 결정짓는 요소이다. KG의 간선은 relation으로 불리고 이는 단순히 entity 사이의 관계를 표현하는 것을 넘어 구체적으로 '어떤' 관계인지 표현해 준다.
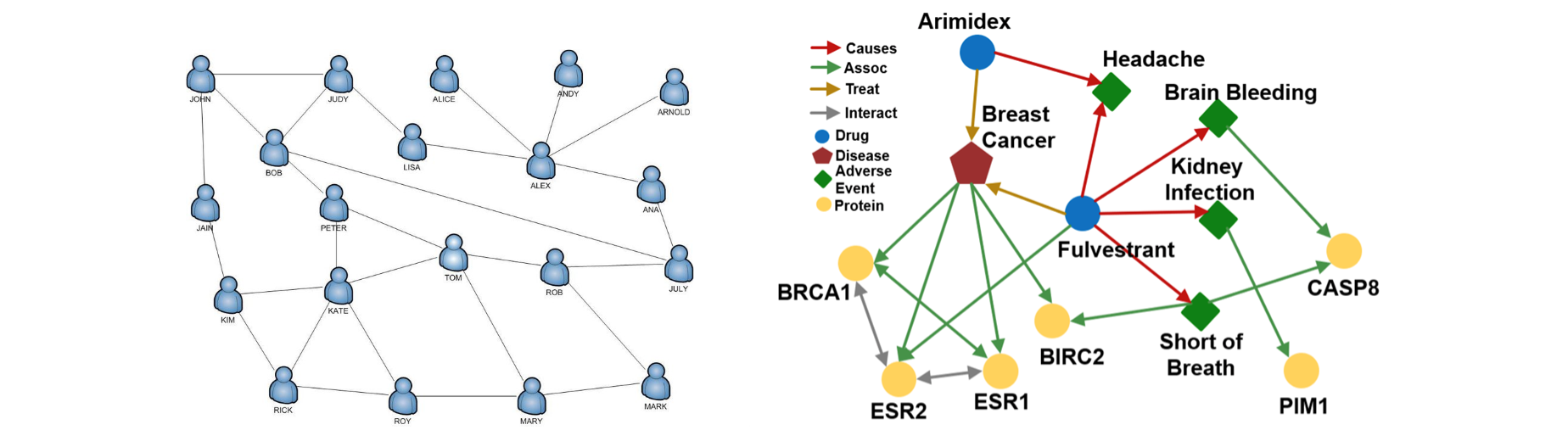
위의 그림을 통해 KG의 표현력을 한눈에 알 수 있다. 왼쪽은 일반 무방향 그래프로 표현된 소셜 네트워크이고 오른쪽은 약물과 병원체, 단백질등의 상호작용과 치료, 원인 등을 나타낸 KG이다. 육안으로만 봐도 오른쪽이 더 복잡함을 알 수 있다. 일반 그래프로 오른쪽 그래프를 모델링해보아라. 아마 주어진 간선의 표현력이 부족하다는 것을 비교적 빠르게 알 수 있을 것이다.
KG의 특성에 따라 데이터의 저장 방식도 사뭇 달라진다. Relation의 종류를 직접 명시해야 하기 때문인데, 일반적인 표현법으로 $start\xrightarrow []{relation} end$를 $(h, r, t)$로 나타내며 이를 triple이라고 부른다. $h, t$는 head, tail을 뜻하고 $r$은 relation을 의미한다.
결론적으로 KG는 더 복잡한 관계성 데이터들을 그래프에서 자유로이 나타낼 수 있는 하나의 구조이다.
3. KGC의 목적과 이유
이와 같이 KG가 풍부한 표현력을 담을 수 있다는 것을 알게 되었다. 이에 따라 자연스럽게 생각난 아이디어가 인터넷에 올라와 있는 정보들을 긁어모아 하나의 KG로 만들면 온 세상을 표현할 수 있는 그래프를 만들 수 있다는 것이다. 이에 부응하기 위해 Freebase, Worldnet, DBpedia, YAGO, NELL 등 다양한 KG 구축 모델들이 제시되었고 일부는 지금까지도 가동하며 세상을 KG로 모델링하기 위해 노력한다. 가동 몇 년 사이에 이 모델들은 수십, 수백억 개의 사실들을 담고 규모까지 성장하였다.
하지만 문제가 있다. 이들이 error-free 하고 complete 하다고 볼 수 없다는 것이다. 실제로 Freebase와 DBpedia의 경우 각각 71%, 66%의 사람에 대해 출생지에 정보가 없다 [2]. 이뿐만 아니라 기본적으로 있어야 할 다양한 relation 정보들이 부족하다는 것이 문제가 되는 것이다. 즉 비어있는 정보들을 채워주자(complete)는 목적으로 KGC가 시작되게 된다. KG에서의 추론을 하는 것이기 때문에 KGR(Knowledge Graph Reasoning)이라고도 불린다.
물론 KGC는 거대 KG들에 국한된 작업이 아니다. Web search, recommendation system, KBQA 등 다양한 분야에서 보조적인 역할을 수행한다.
결론적으로 KGC는 sparse 한 KG에 믿을만한 정보들을 채워 이후에 다른 task를 수행할 때 더 좋은 결과를 얻을 수 있게 도와주는 역할을 한다. KGC를 목적으로 하는 모델들은 주로 아래의 두 가지 task를 잘 수행하기 위해 노력한다.
1. link prediction : find ? for $(h,r,?)$ or $(?,r,t)$
2. relation prediction : find ? for $(h,?,t)$

하나 더 염두에 두어야 할 것은 prediction은 모두 rank로 표현된다는 것이다. 즉 yes/no 문제가 아니라 "?에 들어갈 가장 적합한 entity 또는 relation의 순위"를 알아내는
4. 모델 분류
KGC 모델 아래와 같이 분류한다.

각 모델들에 대한 자세한 설명을 하지는 않을 것이다. 대신 해당 방법론(translation, path, etc.)에 대한 전체적인 생각에 대해 서술하겠다.
또한 기억하기를 바라는 점은 각 접근법에 대한 평가는 개인적인 견해이고 tutorial에 명시되어 있는 논문들에만 국한된다.
4-1. Translation based
Translation based는 entity와 relation을 임베딩으로 변환해 prediction을 하는 방법이다. 모델마다의 차이는 있지만 전체적인 흐름상 triple $(h,r,t)$에 대해서 아래의 값을 최대화하게끔 모델을 학습한다.
$$\textbf{h}\times \textbf{r}\approx \textbf{t}$$
여기서 $\textbf{h},\textbf{r},\textbf{t}$은 각각 entity와 relation의 임베딩 벡터이고 $\times$은 모종의 연산을 의미한다.
위의 접근은 생각해 볼수록 매우 단순하다. 예를 들어 link prediction $(h,r,?)$에서는 $h$와 $r$의 임베딩을 연산해 나온 결괏값을 얻고 그 값과 함께 임베딩 공간에 있는 entity 중에서 가장 가까운 entity를 순서대로 rank 한다.
이와 같은 접근이 KG에서 가능했던 이유는 간선에 attribute를 부여한 덕분이다. 일반 그래프에서 간선의 종류는 많아야 2개이기 때문에 이 접근을 시도해 볼 가치가 별로 없었던 것이고 결국 노드만 임베딩으로 표현되었다. 하지만 KG에서는 relation이 entity만큼 중요한 비중을 차지하고 있기 때문에 relation도 임베딩 공간에서 표현될 수 있게 한 접근 방법이 translation based라고 할 수 있다.
본 접근의 장점은 아래와 같이 기술할 수 있다.
1. 모델링하기 비교적 쉽다. 왜냐하면 entity와 relation을 어떻게 잘 임베딩 공간으로 옮길 것인가만 고민하면 되기 때문이다. 이 말은 즉 앞에서 설명한 $\times$를 어떻게 정의할 것인가 고민하면 된다.
2. 연산하기 간단하고 빠르다. 여타 다른 복잡한 딥러닝 모델들과는 달리 목적이 아주 간단하기 때문에($\textbf{h}\times \textbf{r}$와 $\textbf{t}$사이의 거리를 최소화시키자) 단순성의 장점을 착취할 수 있는 것이다.
단점은 아래와 같다.
1. Transductive 하다. 물론 task를 적용시키려는 KG가 거의 정적이면 큰 문제가 되지 않는다. 그러나 비교적 자주 변화가 일어나는 환경(새로운 entity, relation의 추가)에서는 새로운 요소의 임베딩이 학습되어 있지 않기 때문에 새롭게 training 하여 새로운 임베딩을 만들 필요가 있다.
2. 메모리 비효율적이다. 거대한 dataset인 YAGO3-10의 경우 entity의 개수가 120만 개가 넘어간다. 임베딩 하나당 차원을 200으로 가정하면 200*120만=24억 개의 파라미터값을 관리해야 하는 것이다.
3. 설명 가능하지 않다(black box). 학습이 끝난 벡터 결과물들은 우리에게 아무것도 제공해주지 않는다. 단지 link prediction, relation prediction를 수행할 수 있는 벡터들일뿐 그 본연만으로는 아무런 해석이 가능하지 않다.
4. 그래프 구조적 특성을 이용하지 않는다. 지식 그래프도 엄연히 그래프이기 때문에 활용할 수 있는 구조적 정보들이 풍부하게 있다. 하지만 translation based는 이를 거의 사용하지 못한다.

예를 들어 위의 그림처럼 translation model은 하나의 triple씩 모델에 집어넣어 학습한다. 이는 하나의 triple에 대한 표현 방법을 학습하는 것이지 다른 구조적 정보를 사용하지 못하는 것이다. 그림의 오른쪽은 학습에 들어가는 triple들을 KG에서 분리해 그려놓은 것이다. 왼쪽 그림은 KG의 구조적 정보들이 살아있어 더 풍부한 반면 오른쪽은 그렇지 못한다.
4-2.Path based
Path based는 $h$에서 출발해서 t까지 도착하기 위해 KG에 존재하는 논리적 path(경로)들을 찾아내는 접근법이다. 여기서 path란 연속된 relation들의 조합이다. 물론 $h,t$를 잇는 경로라고 해서 무조건 좋은 경로라고 단언할 수 없다.
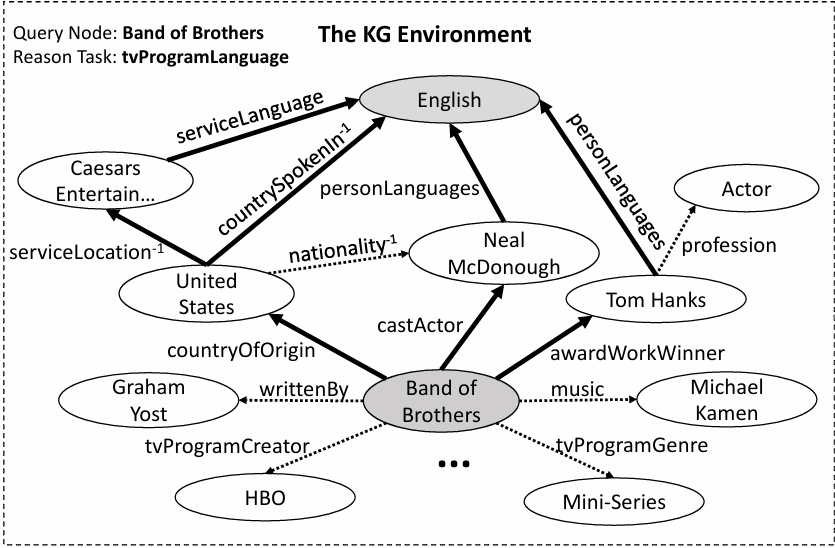
위의 그림[3]에서 Band of Brothers가 $h$이고 English가 t이다. 이때 $h$를 시작점으로 $r$인 $tvProgramLanguage$로 이어질 entity를 찾는 과정을 보여주고 있으며 볼드체 화살표가 찾아진 경로들을 구성하고 있는 relation들이다. 자세히 보면 $h$에서 $t$로 이어지는 모든 경로가 논리적으로 $t$를 추론하는 데에 사용된다고 볼 수 없음을 알 수 있다(e.g., $(countryOfOrigin,nationality^{-1},personLanguages)$).
Translation based처럼 하나의 triple만을 관찰하지 않기 때문에 더 표현력 있는 학습을 할 수 있고 결과의 설명 가능성이 높다.
본 접근의 장점은 아래와 같다.
1. 설명 가능성이 높다. 모델의 학습으로 도출된 결과들은 relation의 sequence, 즉 path이다. Path는 임베딩보다 훨씬 설명력이 높기 때문에 결과의 해석과 모델 디버깅에 효과적이다.
단점은 rule mining의 단점과 함께 설명하겠다.
4-3.Rule based
Path based와 아이디어면에서 많이 유사하다. 특징적인 차이점은 어떤 relaiton $r$을 표현하는 logical rule을 도출하려고 한다. 예를 들어 isGrandmotherOf라는 relation이 있다고 할 때 이를 가장 잘 표현할 수 있는 rule들을 KG에서 관찰해 뽑아내자는 것이다(e.g., $isMotherOf\wedge isMotherOf$). 이를 통해 task를 수행할 때 $(h,r,?)$가 주어졌을 때 $h$를 시작으로 $r$의 rule들을 타고 도착한 entity들이 $t$의 후보들이 되는 것이다. 물론 rule마다의 가중치(confidence)도 train 과정에서 학습하기 때문에 entity rank가 가능하다.
본 접근의 장점은 아래와 같다.
1. 설명 가능하다.
2. Entity independent 하다.
하지만 path based와 더불어 내가 생각하는 단점은 OWA(Open World Assumption)에 별로 부합하지 못한다는 것이다. OWA는 KG에 존재하지 않는 데이터는 틀릴 수도 있고 맞을 수도 있다는 것이다. 이러한 가정을 따르는 이유는 KG가 sparse 하기 때문이다(KGC를 수행하는 이유이기도 함). 즉 relation들이 누락된 부분이 많다는 뜻인데 path와 rule은 relation의 존재에 강하게 영향을 받기 때문에 표현력이 제한 될 수 있다는 우려가 있다.
추가적으로 path based와 마찬가지로 구조적 특징들을 최대한으로 활용하지는 못한다.
4-4.GNN based
그래프의 구조를 활용하는 GNN 기법들을 겸비한 분야이다. 과거에 활발히 연구된 GNN 아키텍쳐들을 KG에서 사용하는 것을 중점적으로 모델링한다.
본 접근의 장점은 아래와 같다.
1. 그래프의 구조적 특징들을 매우 잘 이용할 수 있다.
본 접근의 단점은 아래와 같다.
1. Path, rule based 보다 설명력이 다소 낮을 수 있다.
<이 섹션에서 살펴본 장단점은 tutorial에 나와 있는 모델들에만 국한된 사실임을 다시 명시한다>
5. 마무리
KGC에 대해 공부해 보며 느낀 점은 그래프의 새로운 패러다임에 대해 알게 된 느낌이다. 신나는 점은 일반 그래프보다 더 복잡하기 때문에 모델을 구축하는 측면에서 고려할 수 있는 것들이 다양하기 때문에 시도할 수 있는 도전들도 많다는 것이다. 향후 계획으로 GNN based에 흥미를 느껴 이쪽으로 연구를 진행하지 않을까 생각이 든다.
Reference
[1] Liu, Lihui, and Hanghang Tong. "Knowledge Graph Reasoning and Its Applications." Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2023.
[2] Krompaß, Denis, Stephan Baier, and Volker Tresp. "Type-Constrained Representation Learning in Knowledge Graphs." arXiv preprint arXiv:1508.02593, 2015.
[3] Xiong, Wenhan, Thien Hoang, and William Yang Wang. "DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning." In Proceedings of the Conference on Empirical Methods in Natural Language Pro cessing , 2017.