3.3. Synthetic Regression Data — Dive into Deep Learning 1.0.3 documentation
d2l.ai
[1]
The question is asking me if the batch_size is 8 and I have a data size of 50. Since 50 is not dividable by 8, what should I do to the remaining 2?. Actually the attributes in torch.tensor and even in the list already fixes our concerns. The below is the example of dealing with the unmatched size.
import torch
ls = [*range(100)]
data = torch.tensor(ls).reshape(-1, 2)
batch_size = 8
for i in range(0, len(data), batch_size):
new_batch = data[i:i + batch_size]
print(new_batch.shape)result >>
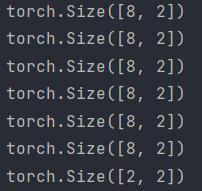
I found this behavior mildly attractive since it automatically senses the final edge of the data tensor and makes the last batch of data with a length of 2.
However if you want to drop out the last batch so that the every mini batch has the same size, we can use drop_last parameter in the torch.utils.data.DataLoader.
"""The new data loader behaves just like the previous one, except that it is more efficient and has some added functionality.
Nothing is special about this section..."""
@d2l.add_to_class(d2l.DataModule) #@save
def get_tensorloader(self, tensors, train, indices=slice(0, None)):
tensors = tuple(a[indices] for a in tensors) # a is the individual data in (self.X, self.y)
dataset = torch.utils.data.TensorDataset(*tensors)
# mainly manages the loading and batching of data, not for viewing the data.
return torch.utils.data.DataLoader(dataset, self.batch_size,
shuffle=train, drop_last=True)
@d2l.add_to_class(SyntheticRegressionData) #@save
def get_dataloader(self, train):
i = slice(0, self.num_train) if train else slice(self.num_train, None)
return self.get_tensorloader((self.X, self.y), train, i)
data = SyntheticRegressionData(w=torch.tensor([2, -3.4]), b=4.2)
for x, y in data.train_dataloader():
print(x.shape, y.shape)
result>>
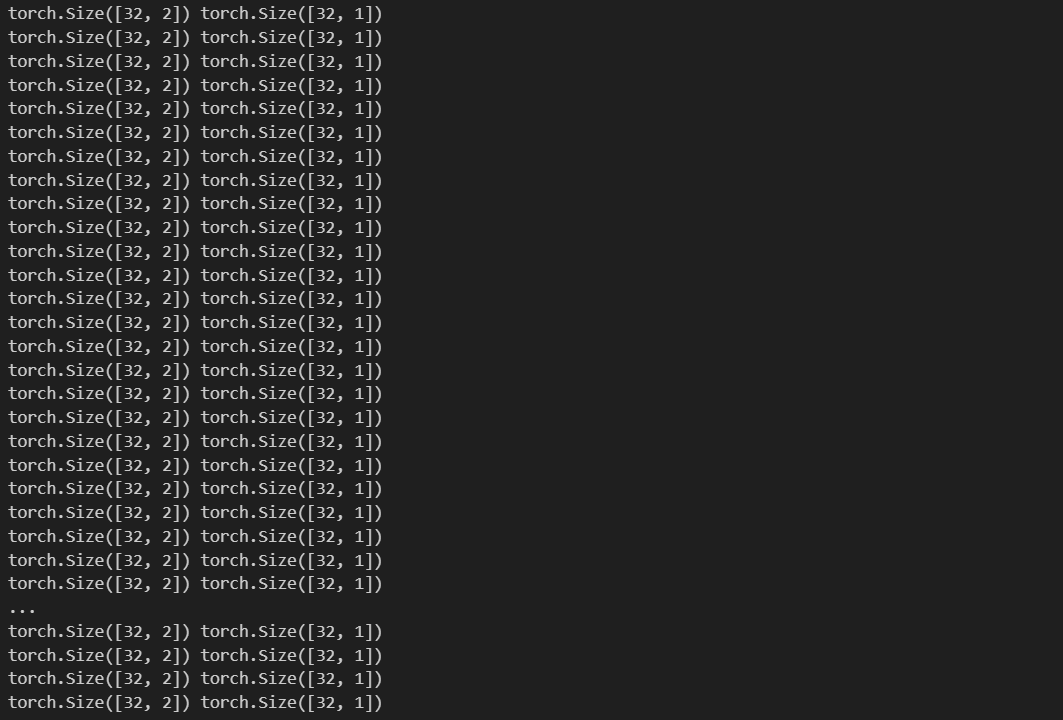
[2]
I didn't even have the capability to read the given paper. I felt so dumb, but atleast I got to study about how pseudorandom work and Feistel permutation.
[3]
We want to implement the get_dataloader to return data whenever the method is called. Our previous methods returned entire datasets, but now we want to return data in batch chunks.
# on the fly, thus generating data whenever it is needed.
class SyntheticRegressionData_onthefly(d2l.HyperParameters):
def __init__(self, w, b, noise=0.01, batch_size=4):
self.save_hyperparameters()
self.w=self.w.reshape((-1, 1)) # for calculation purposes, XT*w+b
def get_dataloader(self, seed): # only makes X and y when the method is called
torch.manual_seed(seed)
X=torch.randn(self.batch_size, len(self.w))
noise=torch.randn(self.batch_size, 1)*self.noise
y=torch.matmul(X, self.w)+self.b+noise
return X, y[4]
The randomness of the data is influenced by the seed of the random function. Thus we have to fix the seed value inorder to erase the randomness.
# on the fly, thus generating data whenever it is needed.
class SyntheticRegressionData_onthefly(d2l.HyperParameters):
def __init__(self, w, b, noise=0.01, batch_size=4):
self.save_hyperparameters()
self.w=self.w.reshape((-1, 1)) # for calculation purposes, XT*w+b
def get_dataloader(self, seed=42): # only makes X and y when the method is called
torch.manual_seed(seed)
X=torch.randn(self.batch_size, len(self.w))
noise=torch.randn(self.batch_size, 1)*self.noise
y=torch.matmul(X, self.w)+self.b+noise
return X, y
data=SyntheticRegressionData_onthefly(w=torch.tensor([2., 3.]), b=2)
prev_X, prev_y=data.get_dataloader()
for i in range(3):
new_X, new_y=data.get_dataloader()
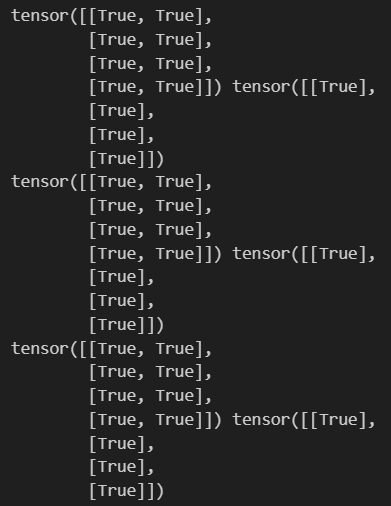
print(new_X==prev_X, new_y==prev_y)
prev_X, prev_y = new_X, new_y
result >>
'ML&DL > Dive into Deep Learning' 카테고리의 다른 글
| [3.6.5] Dive into Deep Learning : exercise answers (0) | 2024.02.15 |
|---|---|
| [3.5.6] Dive into Deep Learning : exercise answers (1) | 2024.02.12 |
| [3.4.6] Dive into Deep Learning : exercise answers (1) | 2024.02.11 |
| [3.2.6]Dive into Deep Learning : exercise answers (0) | 2024.02.09 |
| [3.1.6]Dive into Deep Learning : exercise answers (1) | 2024.01.28 |


