4.1. Softmax Regression — Dive into Deep Learning 1.0.3 documentation
d2l.ai
[1-1]
Since the first derivative of the cross-entropy loss is given, we only have to differentiate $softmax(o)_{j}-y_{i}$ with the respect to $o_{j}$.
$$\partial _{o_{j}}(softmax(\textbf{o})_{j}-y_{i})=softmax(\textbf{o})_{j}(1-softmax(\textbf{o})_{j})$$
[1-2]
Makes sense if the distribution is a Bernoulli. We can view the $softmax(\textbf{o})_{j}$ as the possibility of $o_{j}$ among $o_{k}$ for all $k$ in $q$.
$$softmax(\textbf{o})_{j}=\frac{\exp(o_{j})}{\sum_{k=1}^{q}\exp(o_{k})}$$
If the distribution is not a Bernoulli, the variance will be $\sigma^2=\sum_{i}P(x_{i})(x_{i}-\mu )^2$ where $P(x_{i})$ is the PMF(Probability Mass Function),$\mu$ is the mean of the distribution. I believe employing the probability mass function (PMF) in the variance calculation is more appropriate for the logistic distribution, given that the logit represents a set of discrete values. This approach accounts for the discrete nature of the logit and ensures a more accurate representation of the distribution's variability.
$$\sigma^2=\sum_{i=1}^{q}softmax(\textbf{o})_{i}(\exp(o_{i})-\frac{\sum_{k=1}^{q}\exp(o_{k})}{q})^2$$
[2-1]
Let's say we label each class as binary bits 00, 01, 10. This can be a problem since the distance between 00 and 10 is different compared to 00, 10 and 01, 10, when there are no difference in the probability $(\frac{1}{3},\frac{1}{3},\frac{1}{3})$. Let's see a example.
Assume we have 3 classes A, B, C which has equal probability of $\frac{1}{3}$. Since we use binary, we need atleast 2 bits to represent the class uniquely.However, with equal probability, an ideal code will have an average length of 1 bit per class. Also if we encode A as "0", B as "1", we waste 1 bit for C. This is the inefficiency problem.
There is also a uniqueness problem. If we use {"0":A, "1":B, "00":C} as a decoder, we are not sure whether to decode "00" as AA or C.
[2-2]
For a better code,
1. Use a ternary code. If we use {"-1":A, "0":B, "1":C}, we can avoid the inefficiency and non uniqueness issues.
2. Use one-hot encoding.
[3]
There are 9 possible signals with 2 ternary units. Since we only need 8 classes, 9 is an enough combinations for our case. And these are the benefits of ternary sytems compared to binary.
Reduced Power Consumption: In some cases, ternary circuits can offer lower power consumption compared to binary circuits.
Increased Speed: Ternary systems can potentially process information faster than binary systems for certain operations.
Improved Error Detection: With three states, ternary systems can offer more sophisticated error detection and correction mechanisms.
[4-1]
Assume, w.l.o.g(let $o_{apple}=o_{1}, o_{orange}=o_{2}$), $o_{1}>o_{2}$ apple is the most likely one to be chosen. This is still true with $softmax(\textbf{o})_{1}>softmax(\textbf{o})_{2}$ because
$o_{1}>o_{2}$
$\to \exp(o_{1})>\exp(o_{2})$ (since $\exp()$ is a monotonous function)
$\to \frac{\exp(o_{1})}{\sum_{k=1}^{q}\exp(o_{k})}>\frac{\exp(o_{2})}{\sum_{k=1}^{q}\exp(o_{k})}$
$\to softmax(\textbf{o})_{1}>softmax(\textbf{o})_{2}$
[4-2]
Let's say the score of choosing neither is $o_{3}$. Thus we only have to update $q$ to 3. The $softmax$ function is a generalized form for classification. It can be implemented for more than two classes.
[5-1]
Assume, w.l.o.g, $\log(\exp(a)+\exp(b))>a$
$\to \log(\exp(a)+\exp(b))>\log(\exp(a))=a$ ( since $\exp(b)>0$)
[5-2]
Assume, w.l.o.g, $b=0, a\geq b$ thus we want to minimize the function $f$.
$$f(a)\overset{\underset{\mathrm{def}}{}}{=}\log(\exp(a)+1)-a$$
If we draw the graph via desmos.

We can achieve a small difference between $RealSoftMax$ and $max$ when there is a huge difference between a and b.
[5-3]
$\lambda_{}^{-1}\log(\exp(\lambda a)+\exp(\lambda b))>a$
$\to \log(\exp(\lambda a)+\exp(\lambda b))>\lambda a$
This is the same equation from 5-1 but all the previous $a$ and $b$ multiplied by $\lambda$.
[5-4]
Assume, w.l.o.g, $a>b$.
$\displaystyle \lim_{\lambda \to \infty}(RealSoftMax(a, b), \max(a, b))$
$=\displaystyle \lim_{\lambda \to \infty}\frac{\log(\exp(\lambda a)+\exp(\lambda b))-\lambda a}{\lambda}$
$=\displaystyle \lim_{\lambda \to \infty}\frac{\log(\exp(\lambda a)+\exp(\lambda b))-\log \exp(\lambda a)}{\lambda}$
$\displaystyle \lim_{\lambda \to \infty}\frac{\log(1+\exp(\lambda (b-a))}{\lambda}$
Since $b-a<0$, $\displaystyle \lim_{\lambda \to \infty }\exp(\lambda (b-a))=0$
Thus the above equation is 0 when $\lambda \rightarrow \infty$, which proves the question.
[5-5]
$RealSoftMin(a, b)=\log(\exp(-a)+\exp(-b))$
[5-6]
$RealSoftMinExtend(\textbf{a})=\log(\sum_{k=1}^{q}\exp(-a_{k}))$
[6-1]
The derivative of the log-partition function is the $softmax$ function.
$\partial_{x_{j}}g(\textbf{x})=\frac{\exp(x_{j})}{\sum_{i}\exp(x_{i})}=softmax(\textbf{x})_j$
By 1-1, the derivative of the softmax(second derivative of $g(x)$) is equal to $softmax(\textbf{x})_{j}(1-softmax( \textbf{x} )_{j})$
Since $0\leq softmax(\textbf{x})_{j}\leq 1$,
$\partial_{x_{j}}^{2}g(\textbf{x})>0$, thus it is convex.
[6-2]
$g(\textbf{x}+b)=\log \sum_{i}\exp(x_{i}+b)=\log \sum_{i}\exp(x_{i})\exp(b)$
$=b+\log \sum_{i}\exp(x_{i})=g(\textbf{x})+b$
[6-3]
If some $x_{i}$ are very large, it could be a problem because the coresponding $\exp(x_{i})$ will dominate the sum. Other components that are not as big as $x_{i}$ will not have any specific role in shaping $g(\textbf{x})$.
Here is a 3D graph of a 2 degree log-partiton function $z=\log(\exp(x)+\exp(y))$.
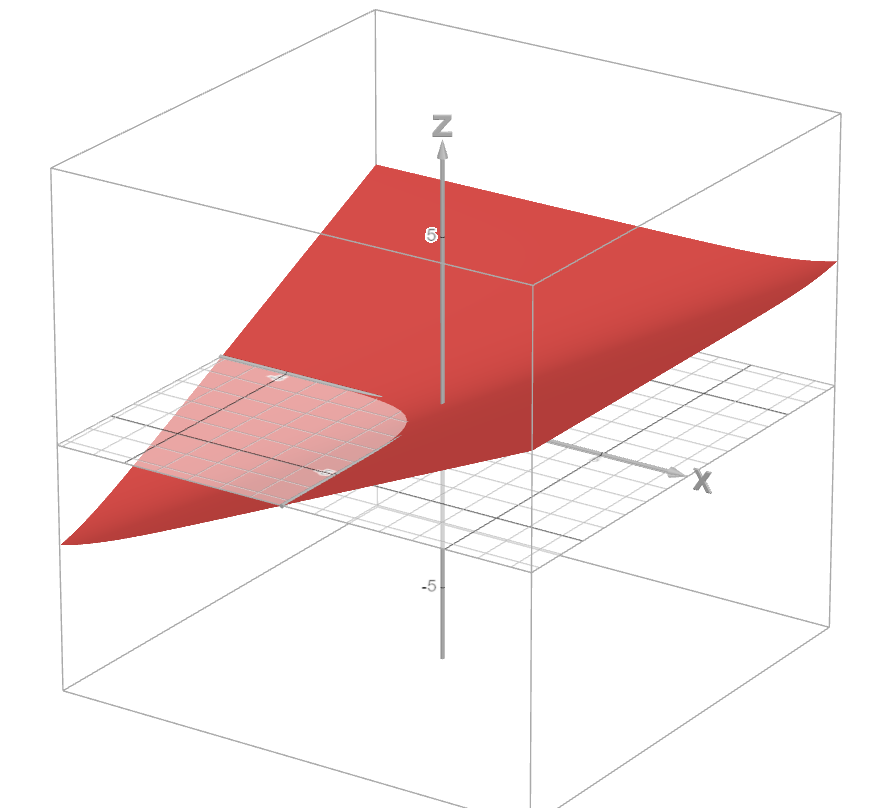
Now see what happens when I amplificate $y$, which will be done by changing the original $y$ to $100y$

We can see that the value of $x$ doesn't really matter when $y$ dominates the function. Which leads to not being able to reflect the influence of $x$.
[6-4]
Let $b=-x_{j}=-\max_{i}x_{i}$
$g(\textbf{x})=g(\textbf{x}+b))-b=\log\sum_{i}\exp(x_{i}-x_{j})+x_{j}$
Before the stable implementation : $\log(e+e^2+e^{100})$
After the stable implementation : $\log(e^{-99}+e^{-98}+1)+100$
This method allows us ot stabilize the function since the most powerful exponent will be $1$. And the maximum difference between the most powerful exponent and the most weak exponent diminishes to 1(max $e^0$, min $e^{-\infty}$).
[7-1]
The Boltzmann distribution $P(i)~e^{-\epsilon_{i}/KT}$, $Q(i)~e^{-\alpha\epsilon_{i}/KT} $
Halving $\alpha$ will have the impact of doubling $T$, and doubling it will have the impact of halving $T$.
[7-2]
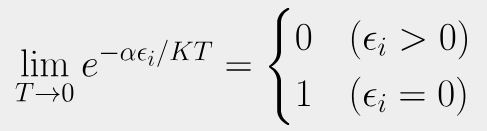
No matter what $\epsilon_{i}$ is, the probability of a particle that has positive energy is close to zero. However particles with zero energy will always be found. Thus all the particles are static(frozen).
[7-3]

Every energy $\epsilon_{i}$ has the same possibility to be found when $T\to \infty$.
'ML&DL > Dive into Deep Learning' 카테고리의 다른 글
| [4.3.4] Dive into Deep Learning : exercise answers (0) | 2024.03.03 |
|---|---|
| [4.2.5] Dive into Deep Learning : exercise answers (0) | 2024.02.29 |
| [3.7.6] Dive into Deep Learning : exercise answers (1) | 2024.02.15 |
| [3.6.5] Dive into Deep Learning : exercise answers (0) | 2024.02.15 |
| [3.5.6] Dive into Deep Learning : exercise answers (1) | 2024.02.12 |

