Paper :
Presentation content :
Main interest
그래프는 노드와 간선으로 이루어져 있다. 노드를 객체, 간선을 객체 간의 연결로 이해할 수 있다. 여기서 더 나아가 지식 그래프(Knowledge Graph, KG)에 대해 살펴보자. 지식 그래프는 객체(entity) 사이의 관계를 간선(relation)으로 정의한 데이터 집합이다. 독특한 점은 간선은 양방향, 방향 간선뿐이며 간선에 종류가 있다는 점이다. 가령 parent_of, is_capital_of 등이 있다. 하나의 triplet (h, r, t) 형태가 데이터 단위가 되며 h -> r -> t 순서로 관계가 정의된다(e.g., (Paris, is_capital_of, France)).

그래서 KG에서 우리가 모델에 학습시키고 싶은 것은 무엇인가? 가장 일반적인 목적은 link prediction이다. 지식 데이터(Knowledge Base, KB)는 크기가 거대하며 incomplete 한 문제 때문에 KB에서 도출한 논리 구조들을 학습하여 빠져 있는 link를 예측해주는 작업이 매우 중요하다. 또한 query가 주어졌을 때 특정 정보를 빼오는 데에 유용하게 사용될 수 있기 때문에 그 중요성은 더 커진다.
이를 해결하기 위해 본 연구에서는 rule mining이라는 relation들의 연속적 관계를 학습해 KB를 학습하는 접근 방법을 선택하였다.
KB의 link prediction은 결국 KG completion 이다. 이는 즉 KB와 인간의 지식 격차를 좁히는 과업이므로 연구가 활발히 진행되고 있다.
what is rule mining?
이를 해결하기 위해 대표적으로 KB에 존재하는 데이터(triplet)들을 이용해서 새로운 것들을 추론해 내는 접근이 있다. 크게 두 가지로 나뉘는데, 첫 번째는 entity와 relation에 대해 임베딩 벡터 또는 텐서를 학습하는 representation learning과 두 번째인 KB에서 동시 발생하는 빈번한 패턴들을 익혀 논리적인 규칙들을 학습하는 rule mining이 있다.

본 연구에서 rule mining, 즉 logic-learning based를 선택한 가장 중요한 이유는 inductive learning이 가능하다는 데에 있다. 하나는 transductive 뿐만 아니라 inductive task에도 적용이 가능하다는 점이다. Representation learning은 학습 과정의 결과로 임베딩을 얻기 때문에 training 과정에서 보이지 않은 entity와 relation에 대해 test를 할 수 없다는 문제가 있다.
또한 logical rule을 학습하는 것 자체의 장점은 인간이 해석 가능한 결과물을 내놓는 다는데에 있다. 가령 임베딩을 학습하는 방법은 임베딩의 결과는 모델의 결과물일 뿐 임베딩 자체가 갖는 의미를 추론할 수 없다. 반면 rule mining은 위의 예시 그림처럼 $brotherOf,fatherOf$ 관계가 결합되면 $uncleOf$를 추론함으로 인간이 봐도 납득 가능한 추론을 도출함을 알 수 있다. 이렇게 mining 된 rule들은 다른 분야의 KB에서도 적용될 수 있을 뿐만 아니라 적은 양, 낮은 퀄리티의 데이터에 대해서도 task를 수행할 수 있는 기반이 되어준다.
그렇다면 rule mining을 어떻게 할까? 전통적으로 미리 정의된 통계적 측정치인 support(특정 rule이 KB에서 얼마나 자주 출현하는지)와 confidence(X->Y에 대해 X가 전제되었을 때 Y가 관찰될 likelihood)로 rule의 신뢰도를 평가한다. 하지만 이 지표들은 rule의 평가에만 기초하기 때문에 rule의 구축까지 이어지지 못한다. 따라서 우리는 rule의 structure($brotherOf\wedge fatherOf\rightarrow uncleOf$)와 그 rule의 score(신뢰도)를 동시에 학습할 수 있어야 한다. 이는 상당히 어려운 문제인데, 왜냐하면 이산적 공간의 structure와 연속적 공간의 score를 동시에 학습해야 하기 때문이다. 이를 해결하기 위해 본질적으로 다른 두 공간을 어떻게 다룰 것이냐가 주안점이다.
Problem with previous works
Rule mining을 위한 초기 시도는 Inductive Logic Programming(ILP)에서 이미 연구가 진행된 바 있다. 하지만 ILP의 요구 사항인 negative example을 충족시키지 못하는 KB의 한계와 scaling 문제를 해결하지 못한다. 이는 representation learning과 차이를 보이는 문제이다. Representation learning에서는 하나의 triplet(KB에 존재한다면 참인 데이터로 판단하는 closed world assumption에 따름)을 기반으로 학습하기 때문에 head entity 또는 tail entity 중 하나를 바꿔서 negative sampling 기법을 사용할 수 있었다. 하지만 rule mining에서는 어떤 rule의 body(structure)가 맞다 틀리고도 학습 전에는 모르기 때문에 classical ILP를 rule mining에 사용할 수 없다.
이와 별개로 Ontological Pathfinding(OP)은 사전에 정의된 metric들인 support, confidence 등을 활용하는 방법이다. 하지만 이도 여전히 사전에 정의된 지표들과 이산 공간과 연속 공간의 결합이 약하다는 제약이 있다.
여기서 더 나아가 representation learning을 기반으로 rule mining을 가능하게끔 한 DistMult 모델이 있다. 하지만 tranductive task에서만 수행 가능하다는 단점이 있었기 때문에 본 연구 이전에 가장 주목받았던 모델은 TensorLog를 기반으로 한 Neural LP 모델이다. Neural LP는 최초로 RNN과 LSTM을 이용해 end-to-end differentiable 모델을 만들었다. 이는 우리가 gradient based optimization을 사용 가능하게끔 해주어 매우 중요한 발전이다. 이 모델은 KB의 일부를 사용해 relation 마다 TensorLog operator를 만들어 structure를 학습하고 이를 연속적으로 곱하여 특정 rule에 대해 학습할 수 있고 score을 최대화 시키는 방향으로 confidence(파라미터)들을 학습시킨다.
하지만 본 연구에서 증명하기를 Neural LP의 방법은 이론적으로 거짓인 rule로 높은 score를 도출할 수 있음을 보였다. 증명은 appendix에 남긴다.
Architecture of DRUM
DRUM의 구조를 바로 알아보기 전에 그 배경에 대해 먼저 살펴봄으로써 본질적으로 이산적인 문제를 어떻게 differentiable manner로 해결하는지 알아보자.
그전에 기호들을 정의하자. Entity의 집합 $\varepsilon, |\varepsilon|=n$와 그에 속한 entity들을 one-hot vector $\textbf{v}_i\in \left\{ 0,1\right\}^n$로 표현하고 $\textbf{A}_{B_r}$는 relation $B_r$의 인접 행렬이다. 즉 $(i,j)^{th}$ 원소는 $\textbf{v}_i$와 $\textbf{v}_j$로 연결되어 있을 때만 1의 값을 갖는다. 또한 relation 집합을 $R$로 표기하자.
어떤 Horn clause를 학습하고 싶다고 하자. 즉 $(x,H,y)$ triple에 대해 body relation을 다음과 같이 구성하는 path를 찾고 싶은 것이다.
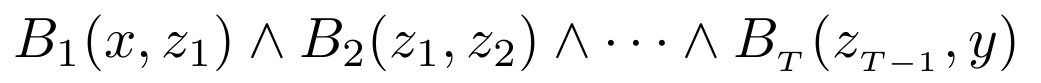
위의 표현은 $\textbf{v}_x^T\cdot \textbf{A}_{B_1}\cdot\textbf{A}_{B_2}\cdots \textbf{A}_{B_T}\cdot\textbf{v}_y$으로 표현될 수 있으며 이 결괏값은 $x,y$를 이어주는 경로($B_{r_i}$, $i$는 step이지만 직관성을 위해 깊이라고 부르겠다)의 개수를 나타낸다. 구체적인 예시는 여기에서 확인하기를 바란다.
참고로 위 표현을 body로 갖고 있는 head relation $H(x,y)$를 closed(모든 variable이 rule에서 2번 이상 나타나야 함) and connected(body가 강한 연결 요소 1개를 이루어야함) rule(a)이라고 하며 우리가 학습 목표로 삼는 rule의 종류이다. 물론 아래와 같이 더 다양한 종류들이 있지만 앞으로 보게될 알고리즘에 의하면 학습 과정을 따를 수 있는 모형은 (a)뿐이다. 물론 그렇다고 해서 (a)의 구조를 갖는 rule들만 학습되는 것은 아니다. 그저 학습의 재료일 뿐이다.

다시 돌아와 각 head relation $H$에 대해 최적의 $\alpha$를 구하게끔 다음 수식을 학습하면 되고

종합적으로 이 수식을 maximize 시키면 된다.

$s$는 최대 길이가 $T$인 잠재적 rule들을 indexing 하고 $p_s$는 $s$를 구성하는 body atom들을 순서대로 저장한 list이다.
하지만 이 방법으로 학습해야 하는 파라미터의 개수($O(|R|^T)$, 이유는 appendix에)가 지수적으로 증가한다. 이는 관측된 쌍 $(x,y)$의 개수를 넘어서 over parameterization의 문제가 발생할 수 있다. 파라미터의 개수를 줄이기 위해 수식 $w_H(\alpha)$을 수정하면

위와 같이 수정할 수 있다. 이는 파라미터의 개수를 $T|R|$로 획기적으로 줄였다. 하지만 이는 길이가 오직 $T$인 rule에 대해서만 학습할 수 있다는 제약이 존재한다. 이를 해결하기 위해 본 연구에서는 아래의 수식을 제안한다.
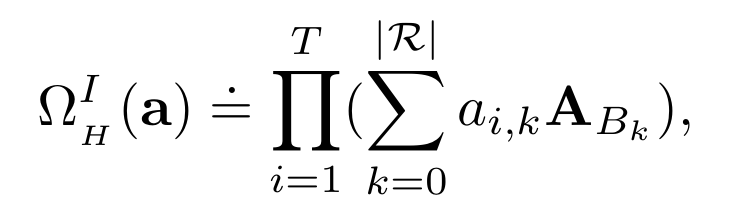
여기서 $A_{B_0}=I_n$라고 정의하면 길이가 $T$ 이하인 모든 rule에 대해 파라미터의 개수 $T(|R|+1)$만으로 학습할 수 있다. 하지만 본 연구의 Theorem 1에 의하면 Neural LP는 물론이고 이러한 구조를 기반으로 하는 모델들은 필연적으로 높은 confidence를 갖는 옳지 않은 rule들을 학습하게 된다.
간단하게 말해, Theorem 1에 따르면 Neural LP가 구한 rule의 list는 순서가 옳바르지 않을 수 있으며 더 나아가 특정 rule의 confidence가 어떤 body atom의 confidence가 높기 때문에 높을 수 있다는 것이다. 이는 rule의 해석 가능성을 저해시키는 요인이다. 실제로 Nerual LP에서 mining 된 rule들이 이 오류에 빠짐을 experiments에서 보이겠다.
단위행렬을 추가해 다양한 길이의 rule을 학습할 수 있는 아이디어만 갖고 와서 파라미터의 개수가 $(|R|+1)^T$일때를 생각해 보자. 이 값은 각 axis의 크기가 $|R|+1$인 $T$차원 텐서로 해석할 수 있다. 구체적으로 어떤 rule의 body가 $B_{r_1}\wedge B_{r_2}\wedge\cdots \wedge B_{r_T}$로 구성된다면 이 rule의 confidence는 $(r_1,r_2,...,r_T)$ 위치의 텐서에 저장되는 것이고 이 텐서를 confidence value tensor라고 하자.
$\Omega_H^I$의 확장으로 얻은 confidence들은 confidence value tensor의 rank-one 근사라고 볼 수 있다. 즉 $T$개의 벡터의 외적으로 이루어진 텐서로 해석할 수 있다는 것인데, 이 해석의 핵심은 "어떤 텐서를 rank-$L$로 근사할 때 $L$의 값이 작을수록 원본 텐서와의 오차가 커진다"와 같은 사실에서 나온다. 따라서 본 연구에서는 low-rank approxximation을 제안하여 우리의 tensor $\Omega_H^I$를 일반화하자는 것이다.

위 식을 사용하면 이론적으로 더 다양한 표현들을 학습할 수 있고 confidence value tensor를 더 정확하게 근사할 수 있게 되는 것이다(여기서 $L$은 하이퍼 파라미터가 되고 물론 $L$을 키울수록 좋겠지만 모델이 무거워지는 것을 감수해야 한다). 이제 $\Omega_H^L$는 $LT(|R|+1)$만큼의 파라미터 개수만 필요하게 되었다. 하지만 이는 하나의 head relation에 대한 파라미터의 개수일 뿐이므로 사실상 총 $LT|R|(|R|+1)=O(|R|^2)$개의 파라미터를 학습해야 하는 것과 다를바 없다. 또한 아직 언급하지 않은 문제점이 $\Omega_H^L$를 직접 optimize 시키면 다른 head relation들과 별개로 파라미터를 학습하기 때문에 하나의 rule을 학습하고 있으면 다른 rule은 학습하지 못하는 한계가 있다.
이제 두 문제점(파라미터 개수, 하나의 head relation의 학습 결과가 다른 head로 전이 되지 못함)의 해결 방법을 설명하기 이전에 배경을 설명하여 맥락을 더 추가해 보겠다.
어떤 쌍의 relation은 같은 rule에 있을 수 없다. 예를 들어 $fatherOf(X,...)$와 $wifeOf(X,...)$는 같은 rule에 있을 수 없다. 왜냐하면 전자는 $X$는 남성, 후자는 $X$가 여성임을 함축하고 있기 때문이다. 이런 정보들은 rule을 mining 함에 있어 유용한 정보가 될 수 있으며 다른 head relation에도 그 학습 결과가 공유되면 좋다. 따라서 head relation의 body atom을 학습함에 이러한 특징들은 매우 중요한 요소임을 알 수 있다.
이러한 관찰들을 토대로 DRUM은 confidence($a_{j,i,k}$) 계산을 위해 $L$개의 bidirectional RNN을 사용한다.

$\textbf{h}, \textbf{h}'$는 각각 forward, backward path의 hidden state이고 0으로 초기화되어있다. Hidden state의 subindex는 깊이를 의미하며 superindex는 bidirectional RNN을 구분 지어 준다. $e_H$는 head relation의 임베딩 벡터이자 이를 구성하는 probabilistic logic rule들을 학습하고자 하는 주인공격이라고 볼 수 있다. $f_\theta$는 hidden state 2개로 깊이 $i$에서의 confidence 값들을 도출하는 fully connected layer이다.

그래서 이 방법이 기존의 문제점을 어떻게 해결해준다는 것인가?
1. 파라미터의 개수
수식적인 측면에서 우리는 여전히 $\Omega_H^L$를 optimize해야 하는 것은 사실이다. 하지만 BiRNN으로 간접적으로 학습시키기 때문에 우리가 사실상 학습해야 하는 파라미터들은 confidence($a_{j,i,k}$)가 아니라 hidden state들과 $f_\theta$의 weight들 뿐이다.
2. Rule의 구성 방향
앞에서도 살펴보았듯이 분명 rule의 구성에도 맥락이 존재한다. 즉 앞에 어떤 body atom이 차지하고 있다면 그 뒤로는 한정된 relation들만 올 수 있는 것이다. NLP에서도 이 "맥락"을 잡기 위해 제안된 것이 BiRNN이기 때문에 본 연구에서도 BiRNN을 사용하였다. 수식을 살펴보면 $f_\theta$ 함수에 왜 $i$ 깊이와 $T-i+1$ 깊이만 포함되냐고 의문이 들 수도 있지만 RNN 특성상 forward 입장에서는 순방향 구성, backward는 body의 역방향 구성을 학습하는 단계 아닌가 추측해 본다.
또한 같은 RNN 구조를 다른 head predicate에 똑같이 적용해 줌으로써 정보가 다른 head로도 전이될 수 있게 해 주었다.
Experiments
DRUM을 statistical relation learning과 KB completion에 대해 평가한다. RNN의 특성상 vanishing/exploding gradient 문제 때문에 DRUM에서는 gradient clipping과 LSTM을 양방향 모두에 사용했다. Neural LP를 따라 KB를 3개의 영역, facts, train, test로 나누어 학습하였다.
Statistical relation learning
데이터 셋은 UMLS, Kinship, Family를 사용하였다.
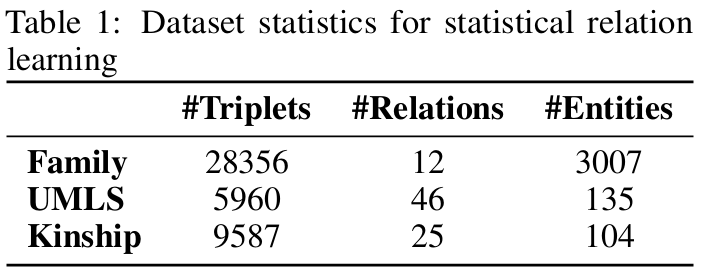
DRUM을 Neural LP와 비교한다. 이때 rank size의 효과를 보기 위해 $L=1$인 DRUM-1과 $L=4$인 DRUM-4에 대해도 실험을 각각 진행해 본다. 다른 representation model 모델들(e.g., ComplEx, ConvE, NTPs, MINERVA)에 대해서 비교를 진행하지 않았는데, 왜냐하면 이들은 inductive 하지 못하기 때문이라고 연구에서 밝힌다. 솔직히 무슨 연관인지는 모르겠다. 리뷰어들의 리뷰를 보니 이 부분을 다들 지적하긴 하는 듯 하지만 아무튼 결과는 아래와 같다.

Knowledge graph completion
데이터 셋은 WordNet(WN18), Freebase(FB15k)와 그로부터 도출된 더 어려운 WN18RR, FB15k-237까지 사용하였다.
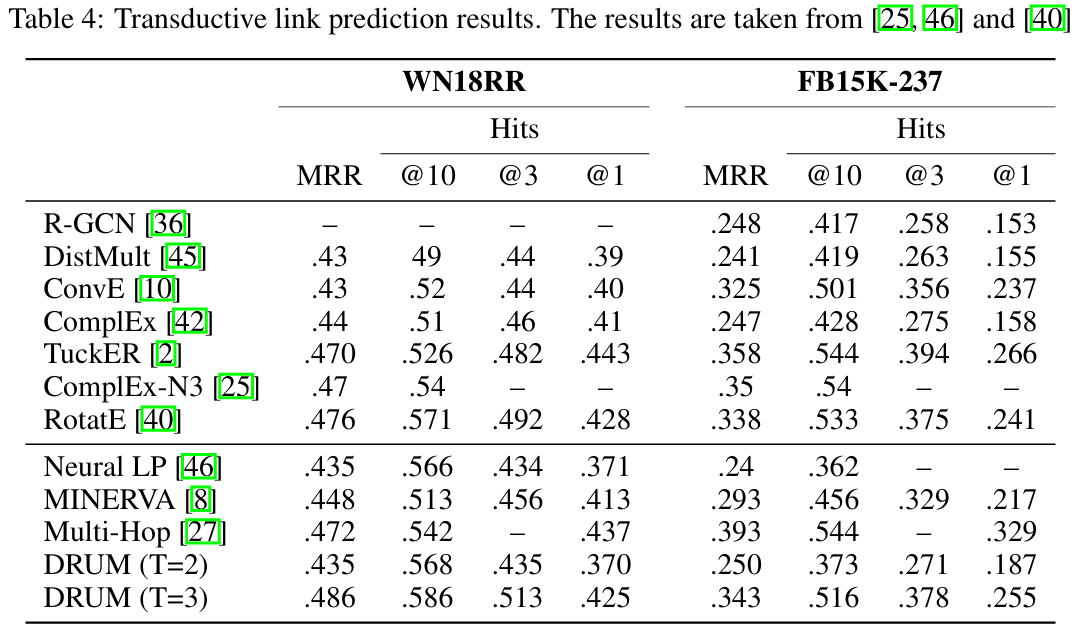
여기서는 DRUM의 rank를 3으로 설정하여 과거의 모델들과 비교하였다.
또한 inductive task에서의 성능 결과가 Table 5에 보인다.

Quality and interpretability of the rules
글 초반에도 설명했듯이 logical rule mining의 장점은 인간이 이해할 수 있는 결과를 도출한다는 것이다. 여기서는 DRUM이 도출한 rule의 quality와 interpretability를 확인하기 위해 family 데이터를 이용해 이를 설명하겠다. UMLS 등의 데이터에도 비슷한 결과를 내놓지만 family 데이터가 이해하기 더 쉽기 때문에 선택하겠다.
연구자들은 2명의 CS학생을 데리고 어떤 모델이 Neural LP인지 DRUM인지 모른 채로 모델을 평가하게 한다. 각 모델의 내림차순으로 정렬된 confidence rule list를 갖고 그들이 생각하기에 틀린 rule이 나올 때까지 맞은 rule의 개수를 세게끔 하였다.

결론적으로 DRUM의 성능이 더 좋음을 알 수 있다.
추가로 두 모델이 특정 head relation으로 도출한 confidence 상위 3개의 rule들을 보았을 때 body의 구조를 살펴보자.

논리적으로 틀린 rule들은 빨간색으로 표시한다. 이는 Theorem 1의 실험적 증명이다. 왜냐하면 Neural LP가 생성한 두 번째로 confidence가 높은 rule은 가장 높은 rule과 body atom을 공유해야 하기 때문이다. 이해가 안되는 점은 head relation은 body atom들과 반대 방향으로 읽어야 말이 된다는 것이다.
Conclusion
DRUM은 Neural LP를 이어 미분 가능한 모델으로써 gradient based algorithm을 사용할 수 있는 모델이다. 기존 Neural LP의 문제점을 bidirectional RNN으로 극복하여 더 논리적으로 해석 가능한 rule들을 mining 할 수 있는 모델이 되었다.
Appendix