Paper :
Main interest
지식 그래프에서의 relation prediction에 집중한다. 이는 즉 두 노드(entity) 사이에 간선(relation)이 존재한다면 어떤 relation이 오는 것이 가장 확률이 높은지 대한 탐구이다. 특히 이 연구에서는 inductive inference가 가능한 모델에 관심을 두고 있다. 즉 transductive inference(Knowledge Graph Embedding, KGE)의 한계를 타파하고 싶다는 것이다.
Problem with previous works
Inductive inference에 대한 더 자세한 배경은 다음과 같다. 초기 knowledge graph completion(link prediction, relation prediction)의 방향은 entity와 relation을 latent space에 임베딩하는 방법이었다. 즉 하나의 link인 $(h,r,t)$를 통해 $h\times r\approx t$를 만족하게끔 임베딩을 구성한다. 하지만 이 접근의 문제점은 크게 2개 있다.
1. Costly 하다. 데이터가 추가되거나 삭제되면 학습이 다시 이루어져야 한다. 왜냐하면 entity나 relation의 임베딩은 학습을 통해 얻어진다. 따라서 새로운 entity나 relation이 데이터에 추가되면 그의 임베딩을 구하기 위해 학습을 매번 다시 해야한다.
2. Entity dependent 하다. 즉 지식 그래프에 있는 relation semantics를 정확히 포착하지 못한다는 것이다. 이에 대한 예시는 아래와 같다.

이와 같은 전개를 logical rule이라고 하며 entity independent 하다. 이를 사용하면 새로운 entity가 데이터에 추가되어도 추론 문제들을 해결할 수 있다. 물론 새로운 relation에 면역 있는 기법은 아니다. 위와 같은 chain-like logical rule을 직접 추출하는 접근도 있는 반면에 본 연구에서는 target relation 주변의 subgraph를 사용해 두 노드 사이의 link를 예측하는 접근을 사용한다.
Architecture
GralL은 SEAL(2018, NeurIPS)과 R-GCN(2017, ESWC)의 확장 모델이라고 할 수 있다. 먼저 모델을 크게 3가지 단계로 나눌 수 있다; 1. subgraph 추출, 2. subgraph에 있는 노드들의 구조적 역할에 따라 라벨 매기기, 3. 앞의 과정을 거친 subgraph를 GNN으로 학습.
1. Subgraph 추출
어떤 subgraph 추출 기반 모델이든 "target 노드 사이에 있는 relation을 추론하기 위한 정보는 subgraph 안에 있다"라는 가정이 있다. Target 노드 주변에서 subgraph를 생성하는 방법은 다음과 같다.
Target 노드를 $u,v$라고 하면 $k$-hop subgraph는 두 노드의 $k$-hop 거리의 이웃들의 교집합에서 $u,v$와의 거리가 $k$를 초과하는 노드들을 제거해 줌으로써 완성된다. 단, directed edge는 이때만 undirected로 취급되며 target edge$(u,r_t,v)$는 잠시 제거된다.
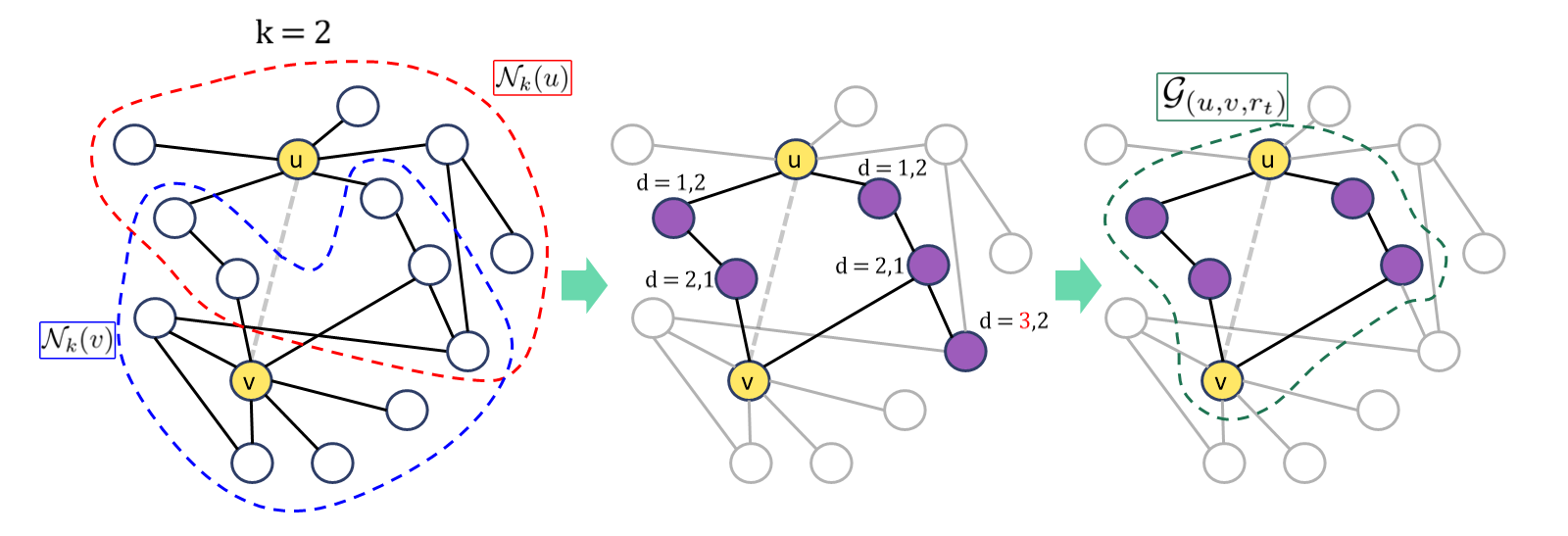
2. 노드 구조적 역할 라벨링
Subgraph를 GNN으로 통과시키려면 subgraph에 있는 노드들에 대한 feature matrix가 있어야 한다. Entity independent 해야 한다는 정신을 이어받기 때문에 entity attribute는 사용할 수 없고 구조적인 정보를 사용한다. 노드의 구조적 역할은 SEAL과 유사하게 target 노드로부터 최단 거리를 사용한다. 예를 들어 노드 $i$에 대한 구조적 정보는 튜플 $(d(i,u),d(i,v))$로 표현되고 이를 사용해 노드 $i$는 $[one-hot(d(i,u))\oplus one-hot(d(i,v))]$로 표현할 수 있다. Target 노드 $u,v$에는 유일성을 위해 각각 $(0,1),(1,0)$을 부여해 주고 따라서 노드 feature vector의 차원은 $2(k+1)$이다. 즉 GNN으로 통과시킬 입력 $\textbf{X}\in \mathbb{R}^{|V|\times d_i}$이 완성된다.
3. GNN
Message passing 구조를 사용한다. 이때서야 target relation을 실질적으로 사용한다. 아래와 같은 인터페이스를 사용하여 노드의 정보들을 임베딩하는 것이다.
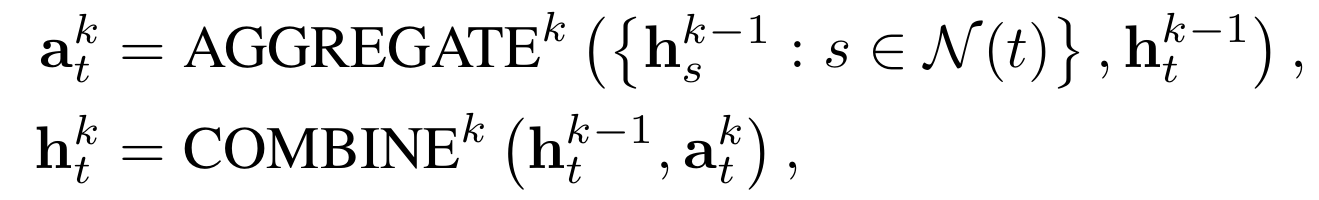
Aggregater를 사용하여 특정 노드 기준으로 direct 이웃들의 가장 최신 state($\textbf{h}_s^{k-1}$)와 자기 자신의 가장 최신 state($\textbf{h}_t^{k-1}$)를 합친다. 이후에 combine을 사용하여 aggregater의 결과와 자신의 state를 통해 다음 state를 출력한다.
AGGREGATE
R-GCN에서 영감을 받아 아래와 같이 구성해 준다.
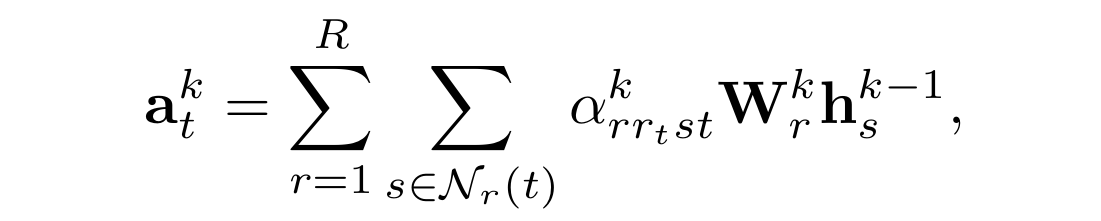
즉 간선마다 attention을 붙여주는데 이는 현재 계산하고자 하는 state의 깊이($k$), 간선의 종류($r$), target relation의 종류($r_t$)에 따라 다른 $s$와 $t$사이의 attention이다. 맥락상 $st$는 표시일 뿐이지 중요한 부분은 아니다. 왜냐하면 $s,t$의 종류에 따라 attention이 다르면 entity dependent 해지기 때문이다. Attention은 아래와 같은 방법으로 구한다.
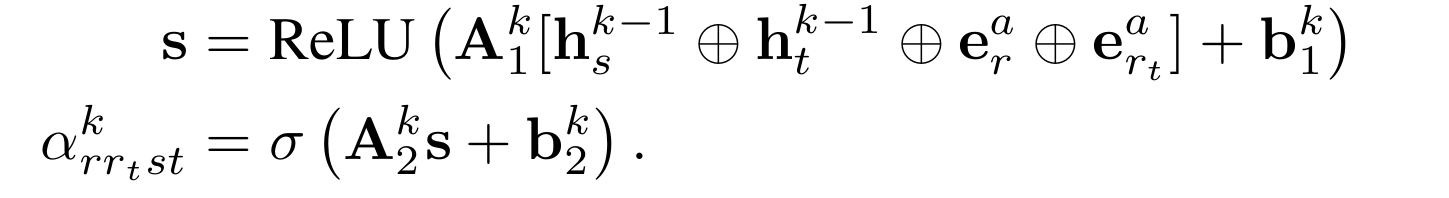
Attention이 normalize 되지 않고 시그모이드로만 통과하여 regulate 하는 것을 볼 수 있다. R-GCN에서 소개된 basis sharing mechanism을 사용해 오버피팅을 방지하고 학습 과정에서 edge dropout을 사용해 이웃들의 정보에 일부만 무작위로 접근한다.
COMBINE

$L$번의 message passing 이후에 subgraph의 임베딩은 노드 임베딩들의 average pooling으로 얻어진다.

이제 최종적으로 score만 내면 된다. 주로 마지막 layer 임베딩만을 사용하여 score를 내지만 intermittent layer 정보도 활용하는 JK-connection을 사용하면 성능이 더 좋아졌다고 한다.
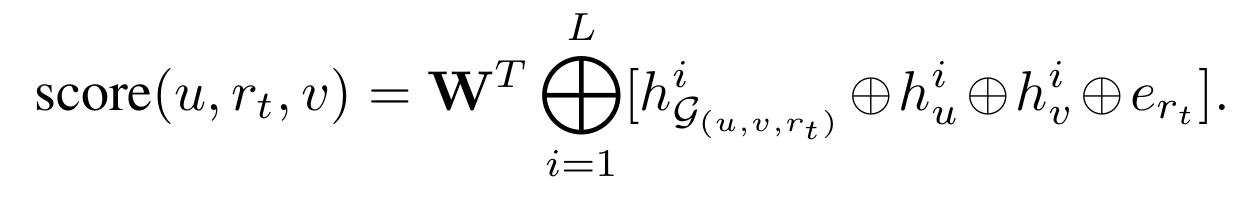
훈련 과정에 대해 설명하겠다. 먼저 dataset에서 triplet(link가 있기 때문)을 기준으로 subgraph를 여러 개 추출한다. 이후에 이를 train, test로 나눈다.
훈련에 사용되는 loss는 아래와 같다.

$p_i$는 train set에 있는 target triple이고 $n_i$는 $r_t$만 랜덤 하게 변형한 triple이다.
Experiments
크게 두 setting에서 실험을 수행한다. 하나는 train subgraph, test subgraph에서 entity가 서로 disjoint(relation은 겹쳐야 함)하게 구성하는 inductive relation prediction과 다른 하나는 entity와 relation 모두 겹치게끔 구성하는 transductive relatin prediction이 있다. 마지막 setting은 KGE와의 동등한 비교를 위해서이다. GralL은 $3$-hop을 사용했다고 한다.
먼저 inductive setting을 보자.

여기서 dataset들마다 v#가 붙어있는데 이는 bias에 robust 한 평가를 위한 것이며 #가 클수록 노드와 간선 개수가 많아진다.
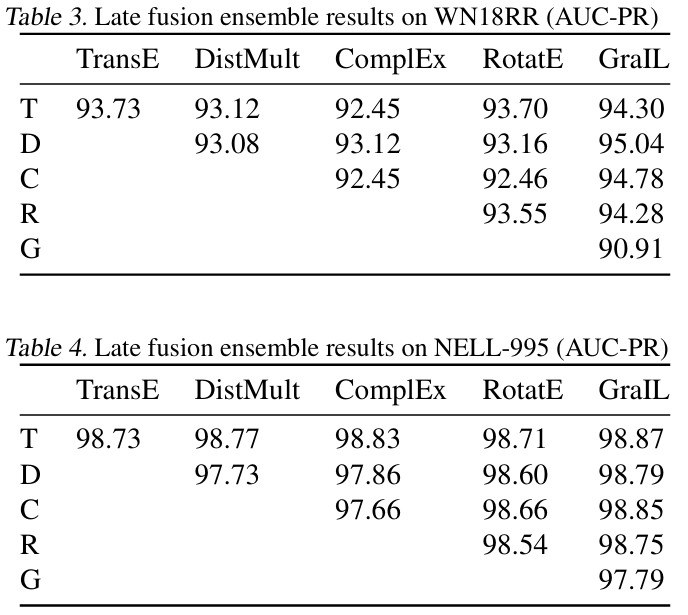
Ensembling을 적용했을 때의 결과이다. Late fusion을 사용했다고 한다.
또한 ablation study까지 진행하였다.

Conclusion
일반 그래프에서 일어나는 link prediction을 지식 그래프에 적용시킴에 의의가 있다. 또한 다양한 타 모델들의 특성들을 적절히 잘 녹여 새로운 모델을 구축하였다.



